
이전 HashSet 포스팅 맨 아래에 적었던 것 처럼, HashSet은 정렬을 지원하지 않는다고 했는데 정렬이 되는 경우가 있었다. 그리고 왜 이렇게 되는 것인지에 대해 의문이 들었다. 그래서 이러한 궁금증에 알아볼 겸 오늘은 LinkedHashSet과 HashSet에 대해 알아보자!
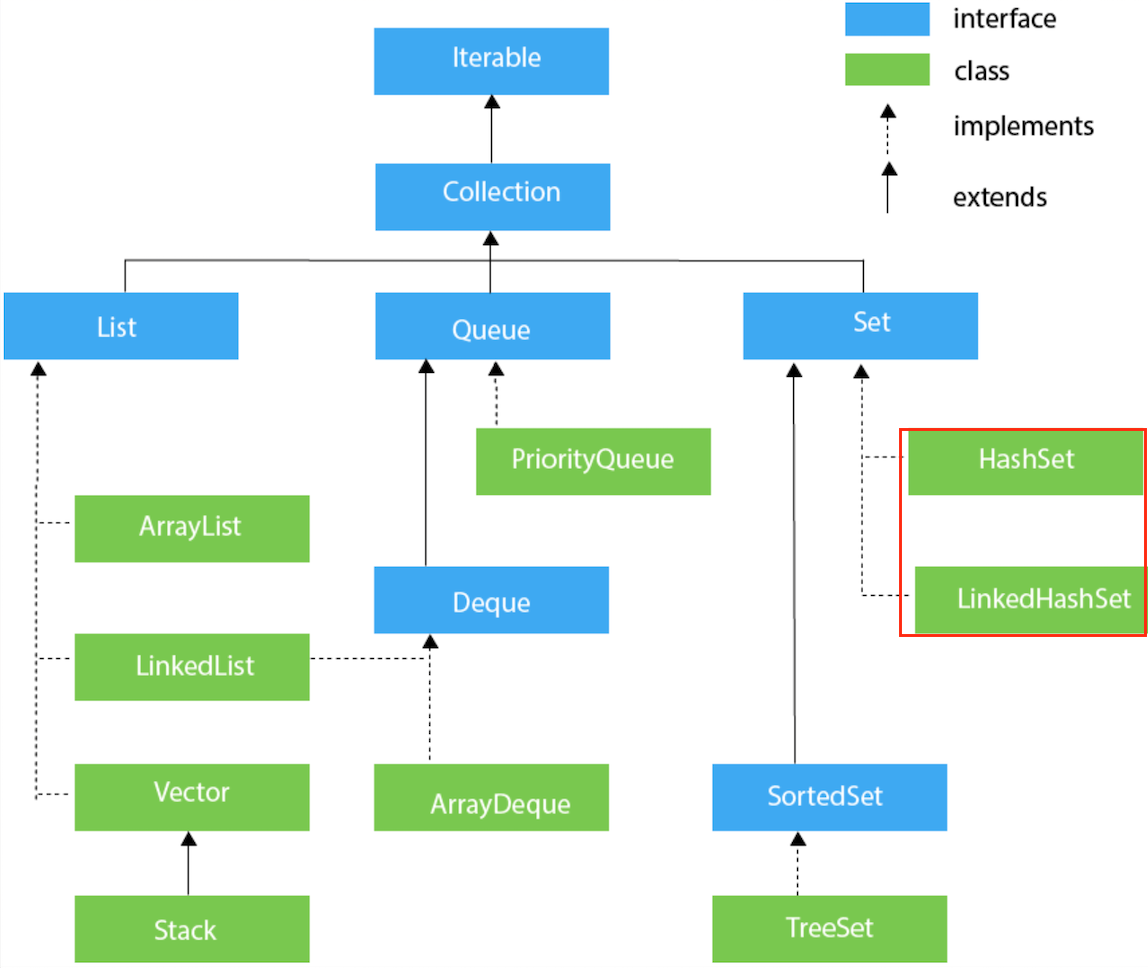
먼저 Set의 종류들에 대해 다시 한 번 살펴보자.
HashSet
- 순서를 보장하지 않는다
- TreeSet보다 삽입, 삭제가 빠르다 (해시 테이블에 원소를 저장하여, 성능 면에서 가장 우수함)
- 내부적으로 HashMap을 사용한다
LinkedHashSet
- 입력된 순서를 보장한다
TreeSet
- 이진 탐색 트리 (Red-Black Tree)를 기반으로 한다
- 따라서 값에 따라 순서가 결정된다 (오름차순 정렬)
- 데이터의 삽입 / 삭제에는 시간이 걸리지만 (HashSet보다 성능이 느림), 검색 / 정렬이 빠르다
즉, 표로 간단하게 정리하면 다음과 같다.
| 인터페이스 | 특징 |
| HashSet | 중복된 요소 저장 X, 순서 유지 X |
| LinkedHashSet | 중복된 요소 저장X, 순서 유지 O |
| TreeSet | 중복된 요소 저장 X, 순서 유지 X, 오름차순 정렬 O |
그런데... HashSet이 왜 정렬(?)되는 것 처럼 보일까?
먼저 다음 경우를 살펴보자
Set<Integer> set = new HashSet<>(Arrays.asList(1, 3, 6, 2, 4, 5));
System.out.println(set); // [1, 2, 3, 4, 5, 6]분명 HashSet은 정렬을 지원하지 않는다고 했는데, 정렬이 되고 있다...!
하지만 여기서 10 이상의 숫자를 넣어보자
Set<Integer> set = new HashSet<>(Arrays.asList(1, 3, 6, 2, 4, 5, 10, 17));
System.out.println(set); // [1, 17, 2, 3, 4, 5, 6, 10]
몇 번을 실행해도 위와 같은 순서로 나온다! 비록 위의 경우 정렬은 되지 않았지만, 랜덤 정렬이 아닌 것을 알 수 있다.
그렇다면, 왜 17이 1의 오른편에 있을까?
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}이를 알기 위해서, HashSet의 add 메소드를 살펴보자.
HashSet은 내부적으로 HashMap으로 구현되어 있다.
final HashMap.Node<K,V>[] resize() {
HashMap.Node<K,V>[] oldTab = table;
/**
* 생략
* */
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
HashMap.Node<K,V>[] newTab = (HashMap.Node<K,V>[])new HashMap.Node[newCap];
table = newTab;
/**
* 생략
* */
return newTab;
}Key에는 저장하고 싶은 객체(데이터)를 저장하고, Value에는 dummy data를 넣어 둔다.
HashMap을 기본적으로 선언하면 디폴트 버킷 사이즈가 16이다. (DEAFULT_LOAD_FACTOR = 16)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16즉 16개의 Node<K, V>가 들어갈 수 있는 배열이 선언된 것이다.
key를 알맞은 버킷에 저장하기 위해 hashCode를 사용한다.
이 hashCode를 버킷 수로 나눈 나머지를 배열의 index로 사용한다.
그럼이제 HashMap의 put 메소드를 살펴보자!
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
아래 예시를 통해 더욱 쉽게 이해해보자. (16이상의 수 부터 16으로 나누는 이유는 버킷 수가 16이기 때문이다)
Set<Integer> set = new HashSet<>();
set.add(6);
set.add(5);
set.add(9);
set.add(3);
set.add(17); // 17 % 16 = 1
set.add(54); // 54 % 16 = 6
set.add(23); // 23 % 16 = 7
set.add(67); // 67 % 16 = 3
set.add(7);
set.add(16); // 16 % 16 = 0
set.add(28); // 28 % 16 = 12
System.out.println(set); // [16, 17, 3, 67, 5, 6, 54, 23, 7, 9, 28]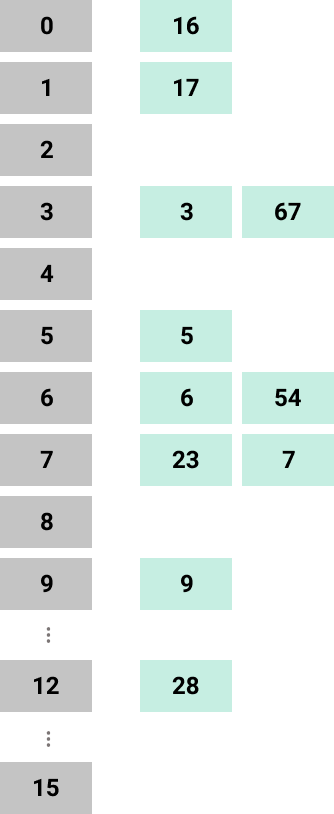
이렇게 0~15까지는 정렬이 되는 것 '처럼' 보이지만, HashSet이 정렬된다는 것은 명백히 거짓이다!
HashSet은 정렬 되는 것이 아니라, 첫 번째 테이블 인덱스부터 순차적으로 탐색하면서 출력하는 것이다.
그렇다면 LinkedHashSet의 경우에는 어떨까?
LinkedHashSet
아래 경우를 비교해보자
Set<String> set = new LinkedHashSet<String>(); // LinkedHashSet 선언
Set<String> set2 = new HashSet<String>(); // HashSet 선언
set.add("Hello2");
set.add("World3");
set.add("Hello1");
set.add("World4");
set2.add("Hello2");
set2.add("World3");
set2.add("Hello1");
set2.add("World4");
System.out.println(set); // [Hello2, World3, Hello1, World4]
System.out.println(set2); // [Hello1, World4, World3, Hello2]HashSet과 달리, LinkedHashSet은 입력된 순서를 유지하고 있는 것을 볼 수 있다.
위에서 했던 예제와 동일한 경우에도 입력 순서를 유지하고 있다.
Set<Integer> set = new HashSet<>(Arrays.asList(1, 3, 6, 2, 4, 5, 10, 17));
System.out.println(set); // [1, 17, 2, 3, 4, 5, 6, 10]
Set<Integer> set2 = new LinkedHashSet<>(Arrays.asList(1, 3, 6, 2, 4, 5, 10, 17));
System.out.println(set2); // [1, 3, 6, 2, 4, 5, 10, 17]따라서 LinkedHashSet은 HashSet의 문제점인, 순서의 불명확성을 제거한 구현체라고 할 수 있다.
[참고]
https://velog.io/@ayoung0073/Java-HashSet%EA%B3%BC-LinkedHashSet-%EB%B9%84%EA%B5%90
'𝑷𝒓𝒐𝒈𝒓𝒂𝒎𝒎𝒊𝒏𝒈 > 𝐽𝐴𝑉𝐴' 카테고리의 다른 글
| [JAVA] Stream API 살펴보기 - findFirst() vs findAny() + 병렬 처리 (0) | 2022.12.01 |
|---|---|
| [JAVA] enum 이란? (0) | 2022.11.29 |
| [JAVA] Collection - Set (SortedSet, TreeSet) (0) | 2022.11.24 |
| [JAVA] Collection - Set (HashSet) (0) | 2022.11.23 |
| [JAVA] Collection - List (Vector) (0) | 2022.11.22 |