

코딩테스트 풀이를 풀다보면 굉장히 많이 다루게 되는 시간 복잡도. 블로그에도 몇 번 언급한 적이 있는데, 어렴풋이 알고있는 개념이지만 오늘 예제를 통해 더 자세히 알아보도록 하자!
시간 복잡도란?
먼저 시간 복잡도란 무엇일까? 컴퓨터 공학에서는 알고리즘의 기본 동작을 실행할 때 특정한 시간이 소요된다고 추정한다. 그리고 시간 복잡도란, 이러한 알고리즘의 동작들을 실행하는 데에 총 소요된 시간을 나타낸 것이다.
쉽게 설명하면 알고리즘 수행에 필요한 단계의 수가 알고리즘의 효율성을 결정하는 주된 요인이라는 것이다. 당연하게 들릴 수 있지만, 알고리즘은 연산이 많아질 수록 그 연산 속도가 오래걸린다. 즉, 시간 복잡도는 알고리즘 내 연산 단계의 횟수의 영향을 받는다.
빅 오 표기법 (Big O notation)
이러한 알고리즘의 시간 복잡도를 쉽게 소통하기 위해 수학적 개념을 차용하여 형식화 한 것이 바로 빅 오 표기법이다. 빅 오 표기법을 사용하면 일관되고 간결한 방법으로 알고리즘의 시간 복잡도를 나타낼 수 있다!
”원소가 N개 일 때 필요한 알고리즘 내 연산이 몇 번, 즉 몇 단계 필요할까?“ 이것이 바로 빅 오 표기법의 핵심 질문이자 정의이다!
위 질문에 대한 답변은 빅 오 표기법에서 괄호 안에 들어가게 된다. 예를 들어, O(N)은 알고리즘에 N번의 단계가 필요하다는 것이다.
O(1) - 일정한(상수) 복잡도
- 원소의 개수에 상관없이 항상 5단계의 연산을 필요로하는 알고리즘이 있다고 가정해보자. 즉 원소가 N개일 때도 연산은 항상 5단계가 필요하다. 그렇다면 이를 빅 오로 표기하면 어떻게 될까?
- 연산이 총 5번 필요하니 O(5)이라고 생각할 수 있겠지만 O(1)이다!
- 대표적으로 stack에서 push, pop을 O(1)이라고 할 수 있다. 왜냐하면 stack 데이터의 크기에 상관없이 맨 마지막(peek) 부분에서 딱 한 번의 연산이 이루어지기 때문이다.
- 코드로 표현하면 다음과 같다.
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
for (int i = 0; i < 5; i++){
System.out.print(i + " ");
} // 1 2 3 4 5

그런데 연산이 5번 필요하다고 했는데 왜 O(5)가 아닌 걸까?
여기서 시간 복잡도의 뜻을 다시 한 번 살펴보면 이런 말이 있다.
‘시간‘의 개념은 단순히 시간이 얼마나 흘렀는지에 대해서 센다기 보다는 '인풋 크기가 증가할 때 복잡성이 얼마나 바뀌는지(the behavior of the complexity when the input size increases)'를 고려해야 한다.
여기서 인풋 크기가 증가할 때 복잡성이 얼마나 바뀐 다는 것은 원소의 수가 증가할 때 단계 수가 어떻게 증가하느냐는 뜻인 것 같다. 즉, 원소가 커질 경우 알고리즘의 단계 수가 얼마나 증가하는 지, 성능은 얼마나 바뀌는 지에 대해 설명할 수 있어야한다.
자 그럼 이러한 관점에서 다시 예시를 봐보자. 원소가 1개(N=1)일 때 연산은 5번 필요하다. 그리고 원소가 100개(N=100)일 때도 연산은 단 5번 필요하다. 이러한 관점에서 바라본다면 연산, 즉 단계의 수는 원소의 개수 증가에 영향을 받지 않는다. N의 값에 상관없이 항상 특정 상수 만큼의 시간(constant time, 여기서는 5)을 가지니, O(1)이나 O(5)이나 본질적으로 같은 알고리즘 유형이라는 것이다.
O(N) - 선형 복잡도
- 알고리즘 연산 단계의 수와 원소의 개수 N이 1:1의 관계를 가진다.
- 즉, N번 만큼의 단계가 필요하고 비례 관계를 가진다. (N이 커지는 만큼 1대1로 정비례하는 듯)
- 대표적인 예로 1중 for문이 있다.
- O(N)의 예시는 다음 코드와 같다.
int[] arr = {1, 2, 3, 4, 5};
for (int i = 0; i < arr.length; i++){
System.out.print(i + " ");
} // 1 2 3 4 5원소가 총 5개(N=5)이고, 반복이 총 5번(N=5) 돈다. 따라서 N번 만큼의 단계가 필요했으니 O(N)으로 표기할 수 있다.
그렇다면 같은 연산을 2번 한다면?
int[] arr = {1, 2, 3, 4, 5};
for (int i = 0; i < arr.length; i++){
System.out.print(i + " ");
} // 1 2 3 4 5
for (int i = 0; i < arr.length; i++){
System.out.print(i + " ");
} // 1 2 3 4 5이렇게 똑같은 코드가 2번 들어갔다. 그럼 이럴 때 시간 복잡도는 어떻게 표시할까? O(2N)일 것 같으나 O(N)이다.
👉 빅 오 표기법에서는 상수를 제외하고 표기하기 때문이다!
O(N)과 O(1)은 얼마나 다를까?
O(1)은 원소의 개수에 영향을 받지 않는 반면, O(N)은 원소의 개수에 따라 알고리즘의 성능에 영향을 받는다! 원소의 개수에 따라 비례관계로 연산 단계 수가 바뀌기 때문이다. 시각적으로 설명하기 위해 아래 그래프를 살펴보자.
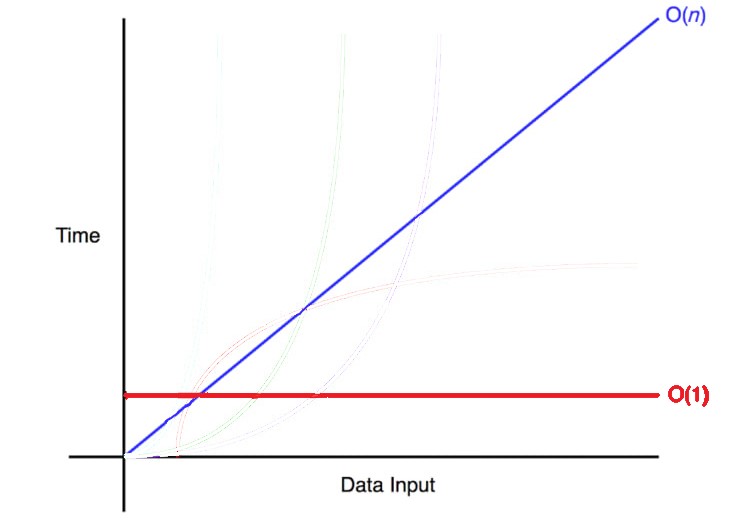
O(N)은 Data Input(원소의 개수)에 따라 Time(시간)이 비례적으로 증가한다! 원소가 하나씩 추가될 때마다 연산이 한 단계씩 더 필요하기 때문이다. 따라서 데이터가 많아질수록 알고리즘에 필요한 단계 수도 늘어난다.
반면, O(1)의 경우, 원소의 개수와는 상관없이 걸리는 시간이 동일하다.
그렇다면, O(1)이 O(N)보다 항상 효율적일까?
원소의 개수에 생관없이 항상 100번 연산을 실행하는 알고리즘이 있다면, 이 알고리즘은 항상 O(N)보다 효율적일까?
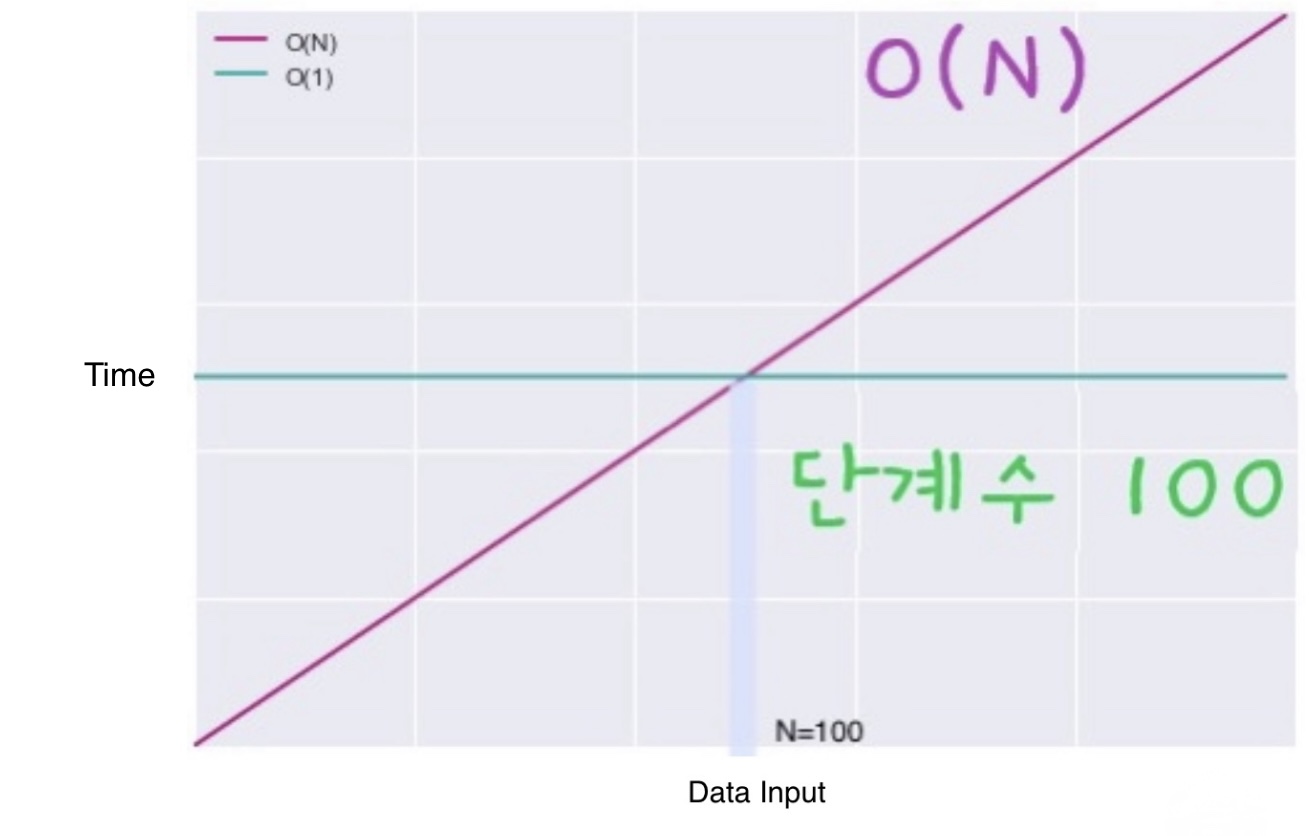
- 원소가 100개 미만(N < 100)일 때는 항상 100번 연산이 필요한 O(1) 알고리즘보다 O(N) 알고리즘이 연산 단계 수가 더 적다.
- 원소가 100개 (N=100)일 때는 두 선이 교차하는 지점이다. 이 경우 O(1), O(N) 두 알고리즘의 단계 수는 동일하게 100단계이다.
- 원소가 100개 초과(N > 100)일 때는 O(N) 알고리즘이 100번보다 더 많은 연산을 필요로 하기 때문에, O(1) 알고리즘보다 항상 더 많은 단계가 걸린다.
물론 원소의 개수에 따라 차이는 있겠지만, 전반적으로 O(N) 알고리즘은 O(1) 알고리즘보다 비효율적이라고 한다. 왜일까?
👉 빅 오 표기법은 최악의 상황을 고려하기 때문이다!
이러한 특징은 비관적인 접근을 위해서이다. 최악의 상황을 대비할 수 있고, 알고리즘이 얼마나 비효율적인가를 알았을 때 알고리즘의 선택에 영향을 미칠 수 있기 때문이다.
O(logN) - 로그 복잡도
- O(logN)은 O(log₂N)을 줄여 부르는 말이다.
- 따라서 연산이 한 번 실행될 때 마다 데이터의 크기가 절반 감소하는 알고리즘 (log의 지수는 항상 2이기 때문)이다.
- 다르게 말하면 N이 커질 수록 단계 수가 logN에 비례하여 증가한다.
- 대표적으로는 이진 탐색(binary search) 알고리즘이나 tree 형태의 자료구조 탐색이 있다.
log₂N
2를 몇번 곱해야 N이 나오는가?
예를 들어 log₂8의 경우 2 * 2 * 2 = 8, 즉 2를 3번 곱해야 8이 나오기 때문에 3이다.
그럼 이진 탐색이란 무엇인가?!
이진 탐색은 정렬된 배열 또는 List에 적합한 고속 탐색 방법이다. 어떠한 방식으로 진행되는가 하니,
"배열의 중앙 값을 확인해, 찾고자 하는 항목이 왼쪽 또는 오른쪽에 있는지 알아내 탐색의 범위를 반으로 줄인다."
이러한 방법을 반복적으로 사용하는 탐색 방법이 이진 탐색이다! 찾고자 하는 값이 속하지 않은 부분은 고려 대상에서 제외하기 때문에 검색해야할 리스트의 크기를 반으로 줄일 수 있는 것이다!
예를 들어 여기서 3을 찾는다고 가정해보자.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
가운데 값인 5와 3을 비교한다. 5 > 3 이므로, 배열의 오른쪽 부분은 고려 대상에서 제외한다.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
고려 대상의 가운데 값인 2와 3을 비교한다. 2 < 3 이므로, 배열의 왼쪽 부분은 고려 대상에서 제외한다.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
3 = 3 으로 3을 찾았다! 탐색 성공!
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
예시 코드를 들어보자면 다음과 같다.
public static int binarySearch(final int[] array, final int searchValue) {
int min = 0; // 시작 Index
int max = array.length - 1; // 마지막 Index
while (min <= max) {
int mid = (min + max) / 2; // 중간 Index
if (array[mid] < searchValue) { // searchValue가 큰 경우 오른쪽에서 탐색
min = mid + 1;
} else if (array[mid] > searchValue) { // searchValue가 작은 경우 좌측에서 탐색
max = mid - 1;
} else { // 탐색 성공
return mid;
}
}
}위의 코드에서는 while 문을 돌 때마다 값을 찾기 전까지 min 또는 max 값을 변경하여, 탐색하는 단계를 약 절반으로 줄이고 있다.
O(1), O(logN), O(N)?

이러한 이진 탐색 알고리즘의 경우, 원소의 개수가 커질 수록 단계의 수는 늘어나므로 이진 검색은 O(1)보다는 덜 효율적이다. 하지만 검색하고 있는 배열의 원소 수(N)보다 단계 수가 훨씬 적으므로 O(N)보다는 훨씬 더 효율적이다. 따라서 O(logN)은 O(1)와 O(N)의 사이에 위치한다.
O(N^2) - 2차 복잡도
- 원소의 값(N)이 증가함에 따라 시간이 N의 제곱수의 비율로 증가한다. 즉, 단계의 수는 원소 값의 제곱이다.
- 구구단을 예시로 들어보자. 1부터 9까지 두 수를 곱한 9x9 곱셈이 필요하다.
- 대표적인 예로 이중 for문, 삽입 정렬, 버블 정렬, 선택 정렬 등이 있다.
- 이해를 위해 2중 for문을 이용해서 간단한 구구단을 코드로 구현해보자.
int n = 9;
for(int i = 1; i <= n; i++){ // 첫 번째 for 문
for(int j = 1; j <= n; j++){ // 두 번째 for 문
System.out.println(i + " * " + j + " = " + i*j);
}
}
// 1 * 1 = 1
// 1 * 2 = 2
// 1 * 3 = 3
// 1 * 4 = 4
... (생략)
// 9 * 8 = 72
// 9 * 9 = 81여기서 N은 9이고, 총 81(= 9*9)단계가 실행되게 된다.
물론 여기서 N에 9 대신 10을 넣으면 총 100(=10*10) 단계가 수행될 것이다.
음,,, 삽입 정렬, 버블 정렬, 선택 정렬에 대해서도 블로그에 정리해보면 좋을 것 같다 (재미있으니까...ㅎㅎ).
여기에 대해서는 지금 정리하고 있는 글들이 끝나면 한 번 정리해보도록 하겠다!
O(2^N) - 기하급수적 복잡도
- O(2^N)는 빅 오 표기법 중 가장 느린 시간 복잡도를 가진다.
- 따라서 구현한 알고리즘이 O(2^N)라면 다른 방법을 찾는 게 좋을 것 같다...
- 대표적인 예는 피보나치 수열이다!
public long fibonacci(int n) {
if (n <= 1)
return n;
else
return fibonacci(n - 1) + fibonacci(n - 2);
}위 코드는 피보나치 수열을 구현한 코드이다! N이 커지면 커질 수록 심각할 정도로 처리 속도가 느리다.
왜냐하면 메소드를 실행할 때 마다 재귀함수를 통해 동일한 함수를 2번 더 실행해야된다.
즉, 1번, 2번, 4번, 8번, 16번 ... 이렇게 단계가 점점 늘어나게 된다 😱
오늘 다룬 빅 오 복잡도들을 그래프로 나타내면 다음과 같다!
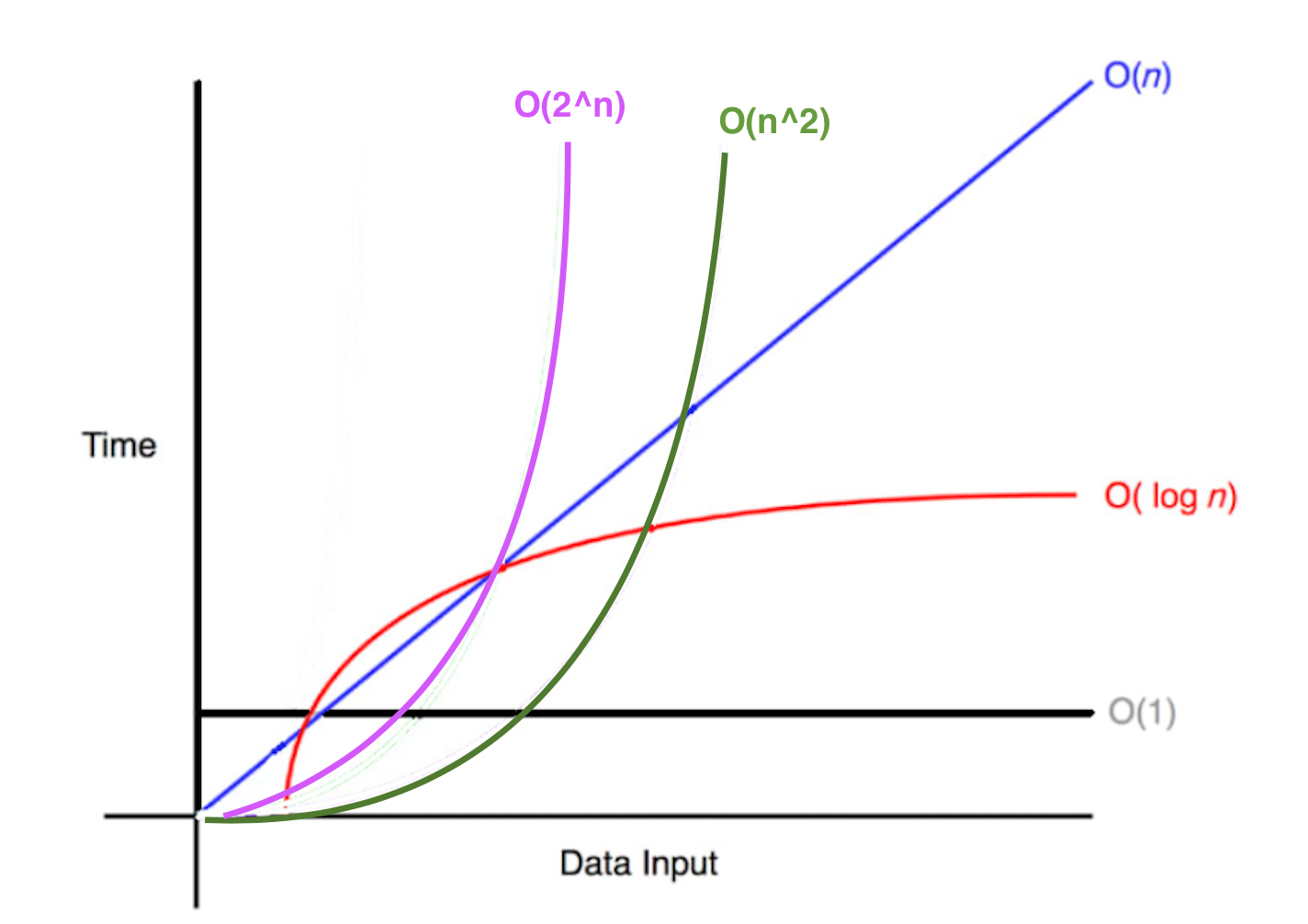
O(1) < O(logN) < O(N) < O(N^2) < O(2^N) 순으로 오래 걸린다. 확실히 O(2^N)의 경우 그래프의 상승폭이 가파르다.
사실 이 포스팅에서 다루지는 않았지만, 팩토리얼 시간 알고리즘인 O(N!)과 N Log N 시간 알고리즘인 O(N logN)도 있다! 이러한 복잡도의 시각화는 이 사이트에 들어가면 상세하게 확인할 수 있는데, O(N!), O(2^N), O(N^2)의 시간 복잡도를 horrible이라고 한다 ㅋㅋㅋ
O(1) < O(logN) < O(N) < O(N log N) < O(N^2) < O(2^N) < O(N!)
왼쪽으로 갈 수록 효율적이고, 오른쪽으로 갈 수록 비효율적이다!
오늘은 드디어 빅 오 표기법에 대해 정리를 해봤다! 항상 모든 개념들은 이렇게 블로그에 직접 타이핑하며 정리하면 기억에 잘 남고, 완전히 내 것이 되는 것 같은 느낌이 들어서 개인적으로 중요하다고 생각하는 개념들은 블로그에 정리를 하려고 하고 있다 :)
그동안 냅다 이중 포문 돌리던 과거의 나를 반성하며,, 앞으로 알고리즘을 짤 때 시간 복잡도를 고려해보도록 하자!
[참고]
'𝑷𝒓𝒐𝒈𝒓𝒂𝒎𝒎𝒊𝒏𝒈 > 𝐶𝑆' 카테고리의 다른 글
| 메세지 큐 (Message Queue) (0) | 2022.11.30 |
|---|---|
| 동기와 비동기, 블로킹과 논블로킹 (0) | 2022.11.30 |