[JAVA] Stream API 살펴보기 - findFirst() vs findAny() + 병렬 처리
REST API를 공부하는데, 한 아이디에 관련된 Task를 가져오는 getTask 메소드를 만들었고, Task를 가져오기 위해 stream() 을 사용해 해당 id를 필터링 후 findFirst() 메소드를 사용하였다. 그런데 findAny()를 사용하지 않은 이유에 대해 질문이 들어왔고, 이에 대해 공부한 내용을 정리하고자 한다.
findFirst()

stream에서 가장 첫번째 값의 Optional을 반환하고, stream이 비어있을 경우에는 empty Optional을 반환한다.
만약 stream에 따로 순서가 없을 경우에는 무작위의 (any element) Optional을 리턴한다.
findAny()

stream의 '일부' 요소를 기술하는 Optional 값을 반환하고, stream이 비어있는 경우에는 마찬가지고 empty Optional을 반환한다.
여기서 findAny() 메소드가 어떤 요소를 선택하게 될 지는 결정되지 않는다. 즉, stream의 어떤 요소든 자유롭게 선택할 수 있는 것이다. 이러한 이유는 병렬 처리(Parallel operations)의 성능을 최대화 하기 위함이다. 또한 소스 상에서 findAny()의 호출이 같은 값을 리턴하지 않을 수 있다. 즉, 고정적인 리턴 값이 필요할 때는 findFirst() 메소드가 더 적절하다.
그렇다면 여기서 말하는 병렬 처리(Parallel Operation)에 대해서 짧게 이야기해보자. 병렬 처리란 멀티 코어 환경에서 하나의 작업을 분할해, 각각의 코어가 병렬적으로 처리(= 프로그램 명령어를 여러 프로세서에 분산시켜 동시에 수행함으로써 빠른 시간 내에 원하는 답을 구하는 작업)하는 것이다. Java 7 이전에는 데이터 컬렉션을 병렬 처리 하기 위해서는 데이터를 분할하고 각각의 스레드로 할당해야한다. 하지만 스레드는 경쟁 상태(race condition)가 발생할 수 있어 동기화가 필요하고, 마지막에는 각 스레드에서 발생한 부분 결과를 하나로 합치는 과정이 필요하다. 하지만 Java 8 이후 부터는 병렬 스트림을 제공한다.
경쟁 상태 (Race Condition)
경쟁 상태란 두개 이상의 프로세스가 공통 자원을 동시적으로(concurrently - 멀티 작업을 위해 멀티스레드가 번갈아가면서 실행; 직렬 처리) 읽거나 쓰는 동작을 할 때, 공용 데이터에 대한 접근이 어떤 순서에 따라 이루어졌는지에 따라 그 실행 결과가 같지 않고 달라지는 상황을 말한다.
병렬 스트림
병렬 스트림은 각각의 스레드에서 처리할 수 있도록 스트림 요소를 여러 청크로 분할한 스트림이다. 때문에 병렬 스트림을 이용하면 멀티 코어 프로세서가 각각의 청크를 처리하도록 할당할 수 있고, 일반적으로 직렬 처리된 스트림보다 더 빠르다.
그럼 다시 본론으로 돌아와서, findFirst()와 findAny()에 대해서 살펴보자.
findFirst()
List<String> list = Arrays.asList("A", "A1", "A2", "B", "C", "D");
Optional<String> element = list.stream()
.filter(s -> s.startsWith("A"))
.findFirst();
System.out.println(element.get()); // A
// 병렬 처리
List<String> list = Arrays.asList("A", "A1", "A2", "B", "C", "D");
Optional<String> element = list.stream()
.parallel()
.filter(s -> s.startsWith("A"))
.findFirst();
System.out.println(element.get()); // A
findAny()
List<String> list = Arrays.asList("A", "A1", "A2", "B", "C", "D");
Optional<String> element = list.stream()
.filter(s -> s.startsWith("A"))
.findAny();
System.out.println(element.get()); // A
// 병렬 처리
List<String> list = Arrays.asList("A", "A1", "A2", "B", "C", "D");
Optional<String> element = list.stream()
.parallel()
.filter(s -> s.startsWith("A"))
.findAny();
System.out.println(element.get()); // A or A1 or A2findAny()에서 병렬 처리의 경우, 멀티스레드가 stream을 처리할 때 가장 먼저 찾는 요소를 리턴하여, 실행할 때 마다 리턴값이 달라진다.
그럼 이러한 차이를 조금 더 직관적으로 알아보기 위해 아래 테스트를 통해 살펴보자.
@Test
void findIdTest() {
DecimalFormat decFormat = new DecimalFormat("###,###");
List<String> list = new ArrayList<>();
for (int i = 0; i < 1000000; i++) {
list.add("A" + i);
}
// findFirst() 병렬
for (int j=0; j<5; j++) {
long start = System.nanoTime();
Optional<String> element = list.stream()
.parallel()
.findFirst();
long end = System.nanoTime();
System.out.println("병렬 수행시간(first): " + decFormat.format(end - start) + " ns | 값 : " + element.get());
}
// findFirst() 직렬
for (int j=0; j<5; j++) {
long start = System.nanoTime();
Optional<String> element = list.stream()
.findFirst();
long end = System.nanoTime();
System.out.println("직렬 수행시간(first): " + decFormat.format(end - start) + " ns | 값 : " + element.get());
}
System.out.println("=======================");
// findAny() 병렬
for (int j=0; j<5; j++) {
long start = System.nanoTime();
Optional<String> element = list.stream()
.parallel()
.findAny();
long end = System.nanoTime();
System.out.println("병렬 수행시간(Any) : " + decFormat.format(end - start) + " ns | 값 : " + element.get());
}
// findAny() 직렬
for (int j=0; j<5; j++) {
long start = System.nanoTime();
Optional<String> element = list.stream()
.findAny();
long end = System.nanoTime();
System.out.println("직렬 수행시간(Any) : " + decFormat.format(end - start) + " ns | 값 : " + element.get());
}
}
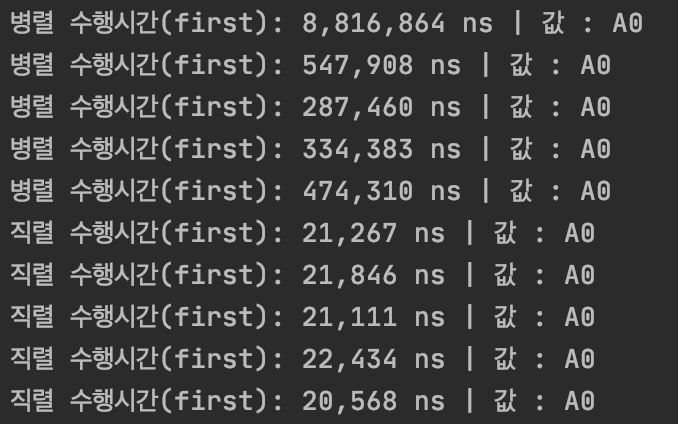

확실히 findFirst() 보다는 findAny()가 더 효율적인 것을 볼 수 있다. 또한 병렬 구조일 때는 findAny()의 효율이 훨씬 뛰어난 것을 볼 수 있다.
HashMap의 경우는 어떨까?
@Test
void findIdTest2() {
DecimalFormat decFormat = new DecimalFormat("###,###");
Map<Integer, String> map = new HashMap<>();
for (int i = 0; i < 1000000; i++) {
map.put(i, "A" + i);
}
// findFirst() 병렬
for (int j=0; j<5; j++) {
long start = System.nanoTime();
Optional<String> element = map.values().parallelStream()
.findFirst();
long end = System.nanoTime();
System.out.println("병렬 수행시간(first): " + decFormat.format(end - start) + " ns | 값 : " + element.get());
}
// findFirst() 직렬
for (int j=0; j<5; j++) {
long start = System.nanoTime();
Optional<String> element = map.values().stream()
.findFirst();
long end = System.nanoTime();
System.out.println("직렬 수행시간(first): " + decFormat.format(end - start) + " ns | 값 : " + element.get());
}
System.out.println("=======================");
// findAny() 병렬
for (int j=0; j<5; j++) {
long start = System.nanoTime();
Optional<String> element = map.values().parallelStream()
.findAny();
long end = System.nanoTime();
System.out.println("병렬 수행시간(any) : " + decFormat.format(end - start) + " ns | 값 : " + element.get());
}
// findAny() 직렬
for (int j=0; j<5; j++) {
long start = System.nanoTime();
Optional<String> element = map.values().stream()
.findAny();
long end = System.nanoTime();
System.out.println("직렬 수행시간(any) : " + decFormat.format(end - start) + " ns | 값 : " + element.get());
}
}


동일한 테스트에서 stream을 돌리는 객체만 HashMap으로 바꿔줬다. 오! 그런데 결과를 보니 확실히 병렬 수행에서 findAny()의 방법이 훨씬 더 효율적으로 나타나는 것을 알 수 있다! 병렬 처리(Parallel operations)의 성능을 최대화한다는 findAny()를 정확히 보여주는 것 같다. 따라서, 굳이 고정된 값을 return 해주어야하는 게 아니라면 findAny()를 이용하는 것이 더 좋아보인다 :)
테스트를 하다가 생긴 궁금증

그런데! 병렬 처리가 일반적으로 직렬 처리보다 빠르다고 했는데 위 테스트 결과들을 보면 직렬 수행시간이 병렬 수행시간보다 훨씬 빠르다!
그래서 병렬 스트림이 직렬 스트림보다 빠르지 않은 경우를 정리해놓은 포스팅을 읽어보았다. 해당 포스팅에 따르면 스트림의 병렬 처리는 스트림을 재귀적으로 분할, 스레드 할당, 부분적인 결과를 하나로 합치는 과정이 필요하기 때문에 직렬 처리보다 항상 빠른 것은 아니다. 직렬 처리가 병렬 처리보다 더 빠른 경우는 다음과 같다.
- 요소의 수가 많고 요소당 처리 시간이 긴 경우.
- LinkedList 처럼 분할을 위해 모두 탐색을 해야하는 경우.
- 프로세서가 싱글 코어일 경우 스레드의 수만 증가하고 동시성 작업으로 진행되기 때문에 오히려 성능이 하락한다.
- 또한 iterate()의 경우, 이전 연산의 결과가 스트림의 입력에 영향을 미친다. 따라서 이전 연산이 완료되어야 다음 스트림으로 넘어갈 수 있기 때문에 분할이 어렵고, 이는 성능 하락으로 이어진다.
- 박싱과 언박싱은 성능을 크게 하락시킨다 (몰랐던 사실..!). 때문에 박싱을 최소화하고 기본형 스트림을 우선 사용해야한다.
- 순서에 의존하는 연산은 스트림에서 많은 비용이 발생한다. 그리고 이것이 바로 순서가 중요하지 않다면 findFirst()보다 findAny()가 좋고, 단순 limit보다 unordered().limit이 더 효율적인 이유이다.
또한 조슈아 블로치의 Effective Java에서는 parallelStream()에 대해 다음과 같이 말한다.
- ArrayList, HashMap, HashSet, ConcurrentHashMap, 배열, int 범위, long 범위에서 효과가 가장 좋다.
- 파이프라인의 종단 연산(terminal operation)이 어떤 것이냐에 따라 성능이 결정된다 - 종단 연산 중 가장 parallelStream의 덕을 많이 보는 것은 reduction 작업과 그다음으로는, 조건에 맞으면 바로 반환하는 anyMatch, allMatch, noneMatch 등이 있다.
- parallelStream은 성능 최적화 수단으로만 사용한다.
즉, 병렬 처리 결과가 무조건 더 좋은 결과라고 할 수는 없는 것 같다. (내가 만든 예제 처럼의 결과 처럼...) 따라서 성능 개선을 위해 parallelStream()을 적용하고자 한다면, 이것이 정말로 성능을 개선시켜줄 수 있는지에 대해 깊게 고민해보고, 테스트도 해본 뒤 적용을 하는 게 맞는 것 같다!
단순히 findAny()와 findFirst()의 차이에 대해 알아보고자 한 공부였는데, 병렬 처리라는 것에 대해서도 겉핥기지만 알아본 것 같아 뜻깊은 시간이었다! 병렬 처리라고 하니 생각나는 알고리즘이 있는데, 이에 대해서는 아직 공부중이다! 공부가 어느정도 끝나면 블로그에 정리해보도록 하겠다.
[참고]