[프로젝트] 데이터베이스 선택 - RDBMS VS NoSQL
6개월 전 진행한 라스트프레시라는 프로젝트에 대해 기술적으로 아쉬움이 많이 남는다...
지금도 많이 부족한 나지만, 다시 코드를 보면 부족한 점이 정말 많이 보인다... ㅠㅠ 공부를 할 수록 어떤 점에서 개선이 필요한지 눈에 보이기 시작하고, '이건 이렇게 할 걸' 하는 후회가 들어, 다음 진행할 프로젝트에 대해서는 무언가를 결정할 때 이유를 생각해보고 정리하면 좋겠다는 생각이 들었다. 그래서 오늘 새롭게 생성한 Project 카테고리에서는, 내가 추후 프로젝트를 진행하면서 생각하고 도입 및 개선한 내용 등을 기록할 예정이다!
다시 본론인 데이터베이스로 돌아와서, 여태 한 프로젝트들도 그렇고 DB에서 MySQL을 사용했었다.
사실 토이 프로젝트를 하면서 Oracle도 사용해 본 적이 있지만, 항상 프로젝트를 하게 되면 MySQL을 사용했던 것 같다.
오늘은 내가 그동안 왜 MySQL을 사용하게 되었는지, 그리고 그게 옳은 선택이었는지 되돌아보고 추후 프로젝트에서는 어떤 DB를 사용할 지 생각하는 시간을 가져보려고 한다.
RDBMS, NoSQL을 선택하는 기준
DB에는 크게 RDBMS와 NoSQL이 있다. 간단하게 이 둘에 대해서 설명해보자면 다음과 같다.
RDBMS
- RDBMS는 관계형 데이터베이스 모델이다. 구글 클라우드에서 정의하는 관계형 데이터베이스는 테이블, 행, 열의 정보를 구조화하는 방식이다. 각 테이블을 조인하여 정보 간 관계 또는 링크를 설정할 수 있는 기능이 있어, 여러 데이터 포인트 간의 관계를 쉽게 이해하고 정보를 얻을 수 있다. 예를 들어, 고객 테이블의 고객 ID를 primary key로 주문 테이블의 고객 ID를 foreign key로 설정하여, 고객 ID를 통해 고객 테이블과 주문 테이블의 연결 관계를 만들어 줄 수 있는 것이다.
- 이러한 장점 덕분에, 데이터 간의 매우 복잡한 관계를 보여주는 데에도 탁월하다.
- 데이터의 ACID성질을 준수한다.
- 하나의 트랜잭션에 의한 상태의 변화를 수행하는 과정에서 안전성을 보장
Transaction(트랜잭션)
데이터베이스에서 기능을 수행하는 하나 이상의 쿼리를 하나의 묶음으로 모아놓는 작업 단위이다.
트랜잭션은 묶음의 모든 작업들을 다 완료(성공)해야 정상적으로 종료된다.
만약 작업 중 하나라도 실패하면, 트랜잭션에 속한 모든 작업이 실패로 판단되어 Rollback한다.
(트랜잭션에 대해서는 나중에 더 자세하게 포스트로 정리해보겠다!)
ACID
- Atomicity(원자성): 한 트랜잭션의 연산이 모두 성공하거나, 모두 실패하는 것. 즉 All or Nothing
- Consistency(일관성): 트랜잭션 실행 전과 이후, 데이터베이스 상태는 이전과 같이 유효해야함. (Integer -> String ❌)
- Isolation(격리성): 모든 트랜잭션은 독립적임. (트랜잭션 수행 시 다른 트랜잭션 작업이 끼어들 수 없음)
- Durability(지속성): 수행된 트랜잭션은 영원히 반영. (런타임 오류가 발생해도, 성공한 트랜잭션의 기록은 영구적)
NoSQL
- NoSQL은 비관계형 데이터베이스이다. 관계형 데이터베이스와 다르게 NoSQL은 규칙 기반의 테이블 형식 방식으로 데이터를 저장하지 않는다. 대신 데이터를 연결되지 않은 개별 파일로 저장하여, 복잡하고 구조화되지 않은 데이터 유형에 사용할 수 있다.
- 확장성이나 속도면에서 뛰어나서 자주 변경되는 데이터를 저장하거나, 다양한 유형의 데이터를 처리하는 애플리케이션에 적합하다.
👉 이전에 진행했던 프로젝트 내에서는 RDBMS(관계형 데이터베이스)를 사용하기로 했었다.
기획한 프로젝트가 데이터 기반의 서비스가 아니었기 때문에 폭발적인 데이터를 저장할 필요가 없었기 때문이었다.
NoSQL의 경우, 대용량 데이터 처리와 같이 특정 상황에 유리하기에 소규모 프로젝트에는 크게 장점을 발휘하지 못한다고 생각했다.
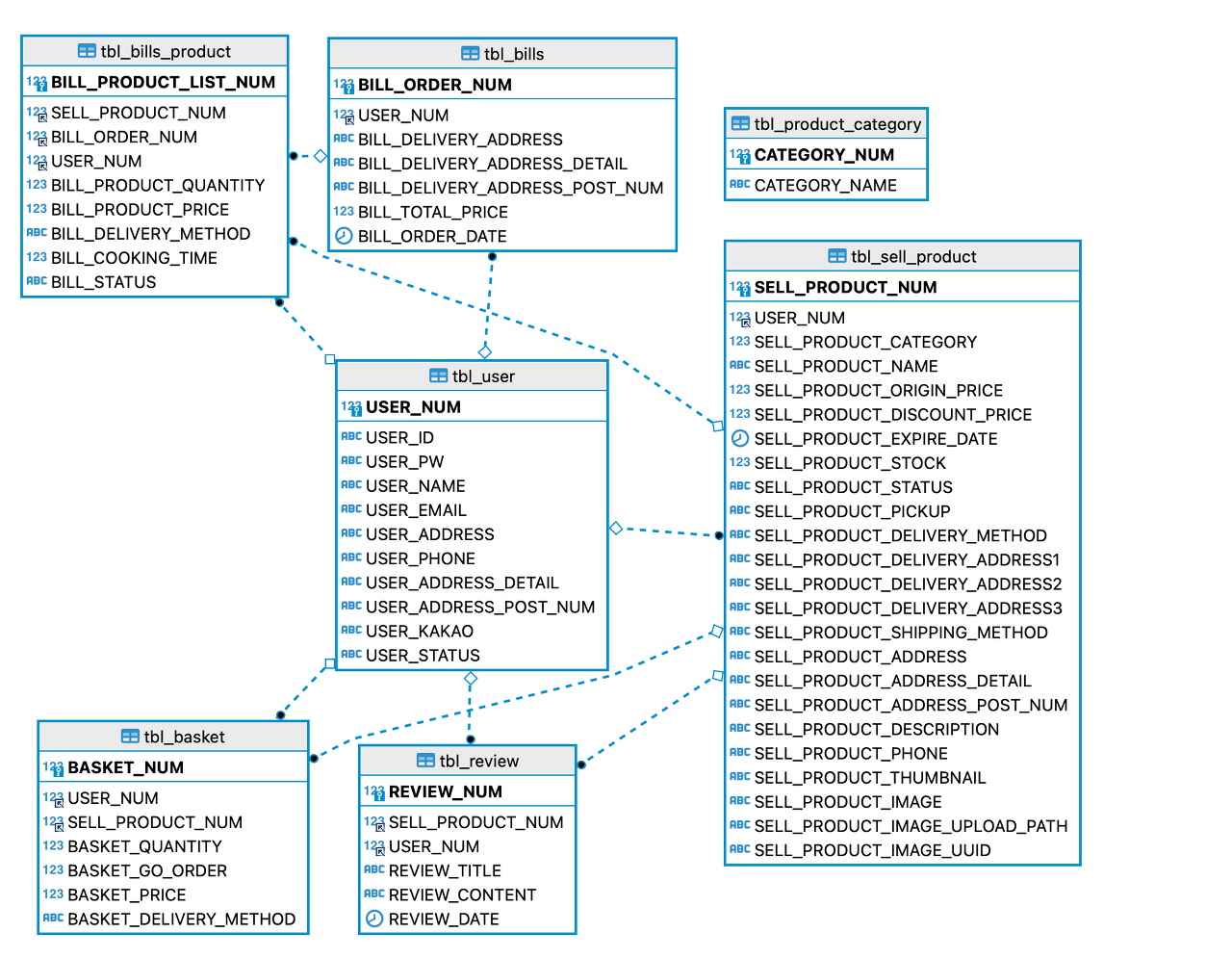
또한 tbl_user와 tbl_sell_product 등 여러가지 테이블들이 서로 관계를 맺고 있었고, 조인 연산이 빈번하게 일어나는 특징을 고려하여 관계형 데이터베이스를 사용했다. 그런데 서비스가 성장해서 대용량 데이터를 다루게 된다는 것을 고려하면, 테이블의 형태가 간단하거나, 읽기 연산이 현저하게 많은 데이터와 같은 경우 NoSQL을 사용하는 것도 흥미로워보인다. 추후 진행하는 프로젝트에서는 각 특성을 생각해 가장 적절한 데이터베이스를 혼합하여 사용해도 괜찮을 것 같다.
그동안 왜 MySQL 을 사용했었나?

관계형 데이터베이스를 사용하기로 마음먹고, 그럼 어떤 데이터베이스를 사용할 것인가?에 대해서 생각했었다.
프로젝트는 실제 창업이 목적이 아니라 학습이기 때문에 최대한 유료인 제품의 사용을 지양하고자 했고, 오라클과 같은 유료 데이터베이스는 고려사항에서 제외했다. MySQL의 경우 무료 버전으로 프로젝트 운영에 충분하기도 했다. 또한 21년 기준 Google, LinkedIn, Netflix, Twitter등의 다양한 기업에서 사용되며 높은 시장 점유율을 가지고 있어, 비교적 쉽게 레퍼런스를 찾을 수 있다는 점이 운영에 더 용이할 것이라 생각했다. 또한 설치가 쉽고, 서포트 커뮤니티가 큰 것 또한 MySQL을 선택하는데 한 몫 했다고 생각한다. 그리고 팀원들이 익숙한 것도 MySQL이기도 했으니까...
그럼 MySQL을 선택한 것은 옳은 선택이었나?
우아한 형제들의 기술 블로그를 참고했을 때, MySQL의 경우 멀티쓰레드 환경 및 제한된 join 방식의 제공으로 인해 복잡한 쿼리나 대량 데이터 처리에는 비효율적이라고 한다. 또한 MySQL은 데이터의 크기가 커질 수록 테이블의 구조 변경이나 인덱스 생성 작업에도 상당한 시간이 소요된다 ㅠㅠ (실제로 대용량 더미 데이터를 넣어 테스트 작업을 할 때, 상당한 시간이 소요되곤 했었다).
그런데 PostgreSQL의 경우 Partial index나 병렬 처리를 지원해서 효율적인 인덱스 관리가 가능하다. 또한 NoSQL 지원 기능도 개선도 되고 있다고 한다. 아직은 MySQL만큼 많은 레퍼런스를 기대할 수는 없지만, 완벽한 무료 오픈소스 DBMS라는 점도 무시할 수 없다...! 그래서 요즘에는 대용량 데이터 처리에 특화되어있는 PostgreSQL을 많이 사용하는 추세인 것 같다.

흠 아무래도 프로젝트를 진행했을 때가 거의 반년 전이라, 기획하면서 대용량 처리에 대해서 고려하지 못했던 것은 맞다.
하지만 '만약 그랬다면?' 이라는 생각을 많이 하고 있는 요즘, 프로젝트가 대용량 처리가 필요한 상황에 부딪힌다면 MySQL보다는 MongoDB같은 NoSQL 혹은 PostgreSQL로 데이터베이스를 이전하는 것도 괜찮은 방법이라고 생각된다. 또한 PostgreSQL은 AWS RDS에서도 지원이 되고 있다! 종합적으로 살펴봤을 때 MySQL 대신 PostgreSQL을 사용하지 않을 이유가 없어보인다.
따라서 현재 기획하고 있는 새 팀 프로젝트에서 팀원들과 MySQL 대신 PostgreSQL을 써보자고 건의해야겠다!