[AI/DL] Image Segmentation
입사 후, 프로젝트에서 DeepLab V3라는 딥러닝 모델을 적용한 경험이 있다.
따라서 모델을 왜 쓰고, 어떻게 훈련을 하고 inference는 어떻게 해야하는 지 등에 대해서 알아보면 좋을 것 같아 이 포스팅을 쓰게 되었다!
먼저 DeepLab V3 는 Semantic segmentation 모델의 일종이다.
그렇다면 Semantic Segmentation이란 무엇일까?
Semantic segmentation에 대해 이야기 하기 전에, Image Segmentaiton은 Object detection과 얼마나 다를까?
오늘은 여기에 대한 궁금증들을 정리해보자!
(추후, DeepLab V3에 대한 내용도 정리 예정이다 ㅎㅎ)
시작하기에 앞서, 아래 이미지를 비교해보자!
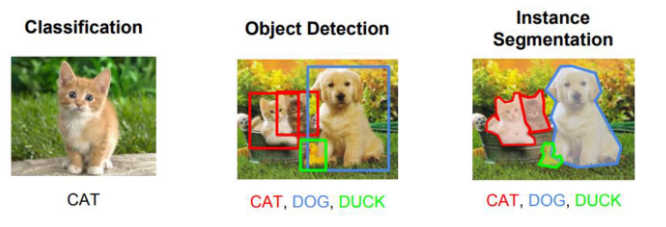
- Classification 은 단순한 이미지 분류, 이미지가 어떤 클래스인지 판별
- Object detection 은 객체 검출로, 입력 이미지가 주어지면 이미지에 나타나는 객체들의 bounding box와 해당하는 카테고리를 예측한다 (위 classification보다 좀 더 고차원 적으로, 이미지 속에 어떠한 class가 어디에 위치해있는지 까지 판별) → 예측해야 하는 bbox(bounding box)의 수가 입력한 이미지에 따라 달라진다.
- Instance Segmentation은 Object detection의 박스 검출에 이어, segmentation까지 수행해야한다. 픽셀별로 어떤 카테고리에 속하는지, 어떤 instance인지 구분할 수 있어야한다.
우리는 여기서 Instance Segmentation과 관련된, 이미지 분할 (Image Segmentation)에 대해 알아볼것이다.
이미지 분할
Image Segmentation은 크게 Semantic Segmantation과 위에서 언급한 Instance Segmentation으로 나눠지게 된다. 두 분류 모두 입력된 이미지 안의 모든 픽셀을 (지정된 개수의) 클래스로 분류하는 것을 목표로 한다.
여기서 픽셀이 동일한 클래스로 분류된다고 하더라도, object 별로 분류 유무를 통해 Semantic, Instance segmentation으로 나눌 수 있다.
- Semantic Segmentation : 동일한 객체는 한 번에 masking
- Instance Segmentation : 동일한 객체들이어도 개별, 즉 Object 별로 masking
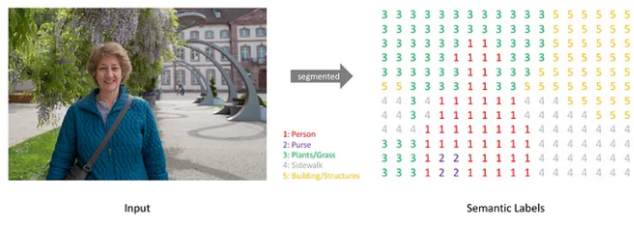
아래 이미지를 참고하면 더 편할 것 같다.

위에도 짧게 언급했지만, DeepLab V3 는 semantic segmentation을 이용한 모델 중 하나이다.
그렇다면 semantic segmentation의 정확한 의미와 목적에 대해 이야기해보자!
- 먼저 대표적으로, Classification (분류)가 있을 것이다. 인풋에 대해 하나의 레이블을 예측하는 작업으로, AlexNet, ResNet 등의 모델이 있다.
- Localization/Detection (발견) 물체의 레이블을 예측하면서, 물체가 어디있는지 정보를 제공하는 작업이다. YOLO, R-CNN등의 모델이 여기에 속한다.
- Segmenation 은 모든 픽셀의 레이블을 예측하는 것으로, FCN, SegNet, DeepLab 등의 모델이 있다.
Semantic Segmentation Task
아래 사진처럼, RGB color 이미지 또는 흑백 이미지가 input으로 주어졌을 때, 오른쪽 이미지 처럼, 각 픽셀별로 어느 class 에 속하는지 레이블을 나타낸 segmentation map을 output 으로 생성하게 된다.
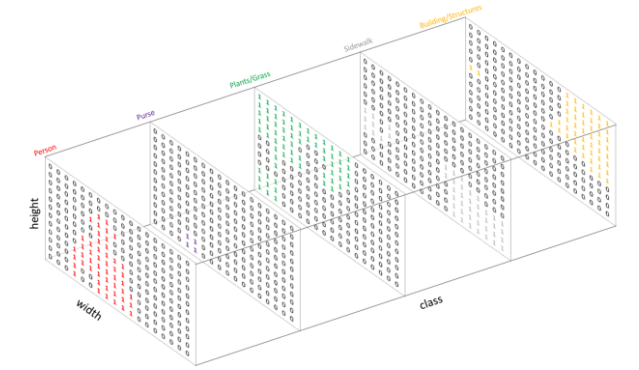
categorical values를 다루는 것과 같이,
One-hot encoding을 통해, 각 class 레이블에 따라 출력 채널을 만들게 되면 아래와 같은 segmentation map을 만들 수 있다.
💡 One-hot encoding (원핫인코딩)
단어 집합의 크기를 벡터 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식
그리고 이러한 segmentation map을 armax 함수를 통해 하나의 이미지로 만들게 된다면
아래와 같이 출력될 수 있는 것이다.
💡 argmax
f(x)를 최대값으로 만들기 위한 x를 구하는 것\

그리고 여기서 단일 출력 채널(Image 2 참고)에서 특정 클래스가 있는 이미지의 영역을 ‘마스크’라고 한다.
오늘은 image segmentation에 대해 간단한 개념 정리를 해보았다!
앞으로도 DeepLab 에 대해 공부하며, 배운 개념들을 블로그에 짧게라도 정리해보려고 한다.
내 공부 기록이 많은 사람들에게 도움이 됐으면 하는 바람이 있다 :)
[참고]
https://medium.com/hyunjulie/1편-semantic-segmentation-첫걸음-4180367ec9cb
https://www.jeremyjordan.me/semantic-segmentation/#dilated_convolutions